Log kroků a poznatků
srpen-září 2020
Zkušební exporty:
- jeden kus OPZ (cca 500 000 řádků z celkem cca 7 mil.)
- vzorek projektů zahrnující různé OP a typy řešených mezer v datech
V datovém exportu jsou následující položky:
prj_id: kód projektuop_id: zkratka OPvalue: kód obce nebo ZÚJ podle číselníku ČSÚ- vysvětlení způsobu rozpadu na třech úrovních
obec_puvod: typ dovození obce (chybějící místo; bez obce; zúžení)rozpad_typ: způsob rozpadu/dovození (kód)rozpad_duvod: bližší zdůvodnění) rozpadu/dovození obce
level: geografická úroveň idenfitikátoru (obec/zuj)radek: pořadové číslo řádků v rámci projektulevel_orig: nejjemnější geografická úroveň, na které byl projekt lokalizován v původních datechid_orig: všechna území, která na této úrovni projekt lokalizovala (oddělená čárkou)chunk: díl souboru (pro export do dílčích XLSX souborů)
Otázky k výstupní datové formě:
Výstup bude mít cca 20 excelových souborů po cca 20 MB. (Lze i větší soubory, ale je to pak pro uživatele dat nešikovné).
- které další položky tam chceme přidat?
- chceme obce podle ČSÚ (př. 554782), nebo podle původních dat (př. CZ010554782)?
- formát (XLSX, CSV?)
- podle čeho rozdělovat do souborů, pokud budeme? (zatím počítám s OP a pak tak, aby v souboru bylo jen cca 500 000 řádků)
Stav:
- hotové překlady všech projektů do obecní úrovně, až na výjimku 119 projektů
- projekty bez místa realizace: rozpadnuty na obce v daných CHKO/NP
- projekty bez údaje o obci: rozpadnuto a dovozeno několika způsoby podle výzev, příjemců, názvu a anotace projektu atd. Kde to bylo možné, je výsledná lokalizace na ZÚJ (městské části), jinak obce
- projekty s více úrovněmi místa realizace: zúženy na obce a ZÚJ
Zádrhele:
- cca 1000 projektů je v původních datech lokalizováno na více než 11 krajů, tj. téměř plošné projekty. Jejich mechanický rozpad na všechny obce generuje obrovské množství řádků
- spousta těchto projektů by při pečlivém třídění šla lokalizovat přesněji, ale muselo by se jít projekt po projektu nebo alespoň výzvu po výzvě, kde ale výzva může být jen několik desítek projektů (výzvy s mnoha projekty jsou v našich rozpadech rozpoznané a ošetřené)
- u některých projektů OP Z na firemní vzdělávání původně lokalizovaných na 11+ krajů jsme museli udělat úvahu, že se dějí pouze v místě sídla - většinou takové určení bylo nesmyslné (malé firmy), ale někde to mohlo být realistické (státní podniky, velké firmy)
- u projektů, které jsme do obce zařadili podle detekce geografického názvu v názvu nebo anotaci projektu bude malé množství falešných pozitiv - např. pokud v anotaci stojí, že projekt se týká území “mimo ORP Blansko”, projekt je přesto rozpadnut na obce ORP Blansko, protože běžnou technologií není možné tyto nuance spolehlivě zachytit.
Pokud by se ukázalo, že toto je velký problém, je možné se u projektů s takto dovozenou obcí vrátit k původním údajům (viz popis položek výše).
To do:
- detailnější popis výstupních dat
- včetně toho, jak jednotlivá dovození obcí fungují a kde může být problém
- aktualizace technické dokumentace
- sestavit mechanismus na rozřešení těch (zatím) 119 projektů, které mají nesouvislou lokalizaci
10. 8. 2020
Kontrola interní validity názvů a identifikátorů
Tj. odpovídají názvy územních jednotech v našich datech těm názvům, které pod stejným identifikátorem najdeme v číselnících ČSÚ?
téměř vše OK
Jen u několika desítek míst lehce neseděly názvy - velká a malá písmena, název Horní u Dolní vs. jen Horní atd. Pro lepší napojitelnost na další data ČSÚ jsem se rozhodl data upravit směrem ke konformitě s ČSÚ.
Kontrola validity geografické hierarchie
tj. jak časté jsou projekty, které se realizovaly např. zároveň v kraji X a obci O, která neleží v kraji X?
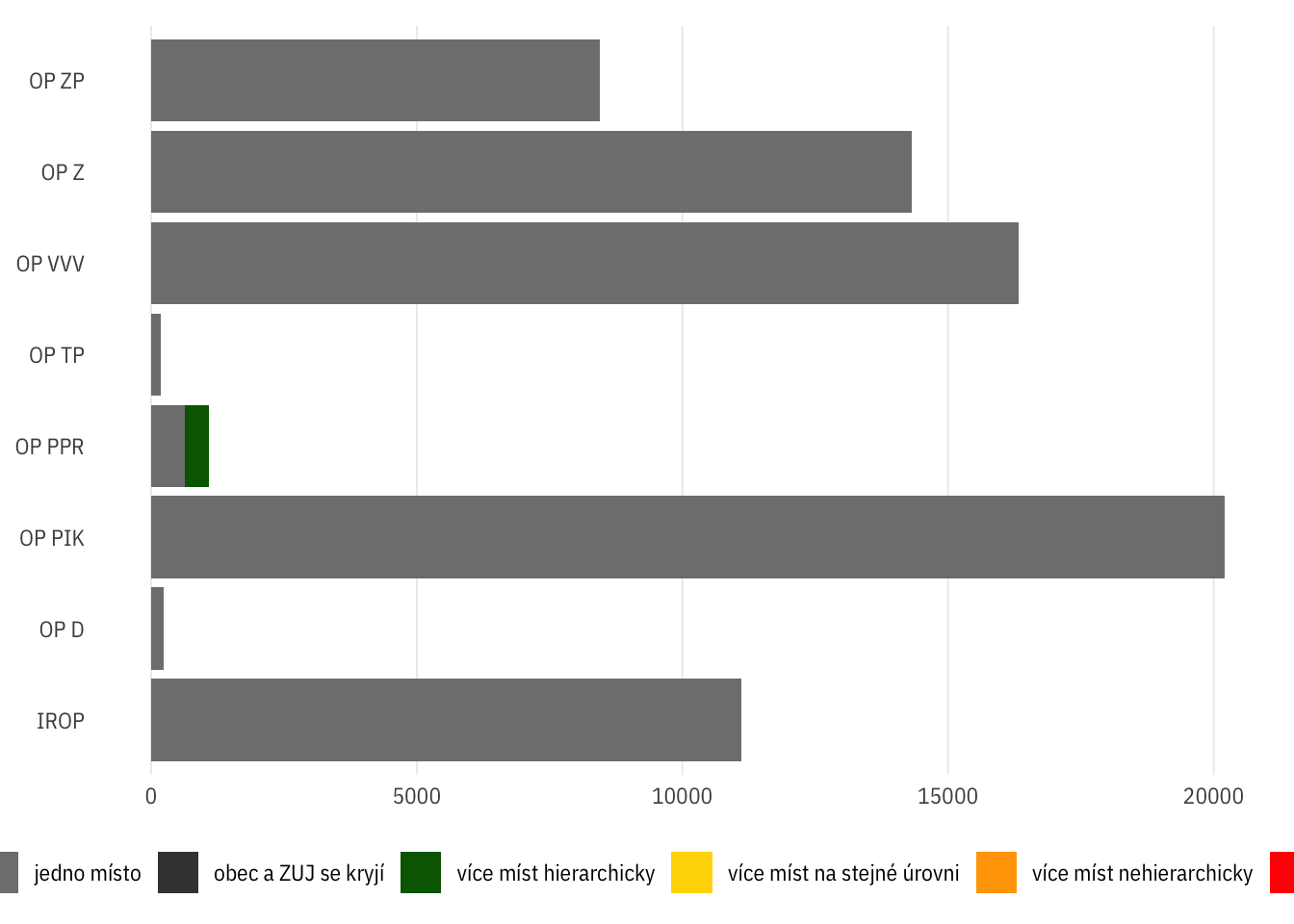
Graf absolutních počtů projektů podle OP a kombinace území
Není to příliš časté, ale život nám to zkomplikuje
máme asi 500 projektů (tj. < 1 % z celku), u kterých jsou uvedena místa realizace na různé administrativní úrovni a zároveň tato místa neleží v jedné hierarachické lince. Nejčastější je to u OP VVV a OP ŽP, něco málo též u OP D a OP PIK.
Díky tomu ale máme nachystané datové struktury a algoritmy na libovolné porovnávání, rozpadání atd. míst realizace v různých kombinacích počtů a úrovní.
Další krok bude rozčlenit těch cca 500 komplikovaných projektů (nejspíš podle výzev) a udělat nějakou úvahu o tom, jak s nimi naložit při finální akokaci místa realizace.
29. 5. 2020
Hromadné načtení dat a základní kontrola
vše OK
Kontrola interní validity dat
V datasetu je 85 146 projektů na celkem 147 683 řádcích; rozložení mezi OP dává smysl.
Existuje cca 200 projektů, u kterých známe sídlo příjemce, ale neznáme jeho název.
Existuje cca 46 projektů, u kterých neznáme sídlo příjemce.
Některé subjekty (zahlédl jsem, nepočítal systematicky) mají v různých projektech různá sídla
Ale to je asi OK.
To by neměla vadit, pokud zrovna u těchto projektů nebudeme muset dovozovat místo realizace ze sídla.
Existují 2 projekty OP PIK, kde číslo projektu obsahuje jen finální číselnou část.
Vadí, nevadí?
24 projektů nemá žádné místo realizace: 1 z OP Z, 23 z OP ŽP.
Část jsou velké plošné projekty AOPK, část lokální, které by šly alokovat podle příjemce.
Validace dat proti číselníkům
OK, ale vyžadovalo dost úprav, aby kompozitní identifikátory obcí a ZUJ seděly proti číselníkům
je třeba vyřadit jeden projekt OP Z s místem realizace v Polsku
Je to ale logické, je to projekt z výzvy na mobility.
Ještě nás čeká kontrola interní validity geografických názvů
tj. jestli místo s ID X má stejný název v datech a v ofiko číselnících
…a kontrola interní validity administrativně-prostorové hierarchie
tj. jestli někde nejsou projekty rozpadnuty do území, které neodpovídají jejich (zadaným nebo intuitivně smysluplným) nadřazeným geografickým jednotkám.
Explorace struktury geografických informací v datasetu
Zhruba 10 tisíc projektů je označeno ve více než jedné geografické úrovni
Dominantní je to u OP PPR, relativně časté u IROPu, OP D a OP ŽP.
S těmi tedy budeme muset zacházet specificky - např. kontrolovat, jestli nižší a vyšší jednotky do sebe zapadají.
Další otázky do následujících kroků
- v jaké formě se budou vkládat nová data?
- nové soubory, stejná forma, jen nové řádky
- stejné soubory, doplněné řádky
- jinak
- očekáváme další OP?
- co přeshranička?