Analýza projektů s nehierarchickou lokalizací
dt <- read_parquet(here::here("data-processed",
"misto_fix-02-gnames.parquet"))
dtl <- read_parquet(here::here("data-processed",
"misto_fix-02-gnames_long-geo.parquet"))source("read_metadata.R")Výskyt divných projektů v různých skupinách
prjs_geostatus <- read_parquet(here::here("data-processed",
"projects-geo-check-groups.parquet"))
places_geostatus <- read_parquet(here::here("data-processed",
"places-geo-check.parquet"))
ops <- read_parquet(here::here("data-processed",
"op-codes.parquet"))
prj_meta <- read_parquet(here::here("data-processed",
"prj-esif-meta.parquet"))head(prjs_geostatus$prj_id) # memo jak vypadá číslo projektu## [1] "CZ.06.1.42/0.0/0.0/16_030/0005269" "CZ.06.1.42/0.0/0.0/16_030/0005330" "CZ.06.1.42/0.0/0.0/16_030/0005331" "CZ.06.1.42/0.0/0.0/16_031/0005096" "CZ.06.1.42/0.0/0.0/16_031/0005101" "CZ.06.3.33/0.0/0.0/16_036/0006175"prjs_groupable <- prjs_geostatus %>%
separate(prj_id, sep = "/", into = c("prog", "obj", "what", "vyzva", "proj"),
remove = F) %>%
separate(vyzva, sep = "_", into = c("vyzva_rok", "vyzva_cislo"), remove = F)## Warning: Expected 5 pieces. Missing pieces filled with `NA` in 2 rows [37325, 37326].Podle OP
prjs_groupable %>%
filter(geostatus == "více míst nehierarchicky") %>%
count(op_id, sort = T)Podle OP a roku
prjs_groupable %>%
filter(geostatus == "více míst nehierarchicky") %>%
count(vyzva_rok, geostatus, op_id) %>%
ggplot(aes(vyzva_rok, n, fill = op_id)) +
geom_col() +
facet_wrap(~geostatus)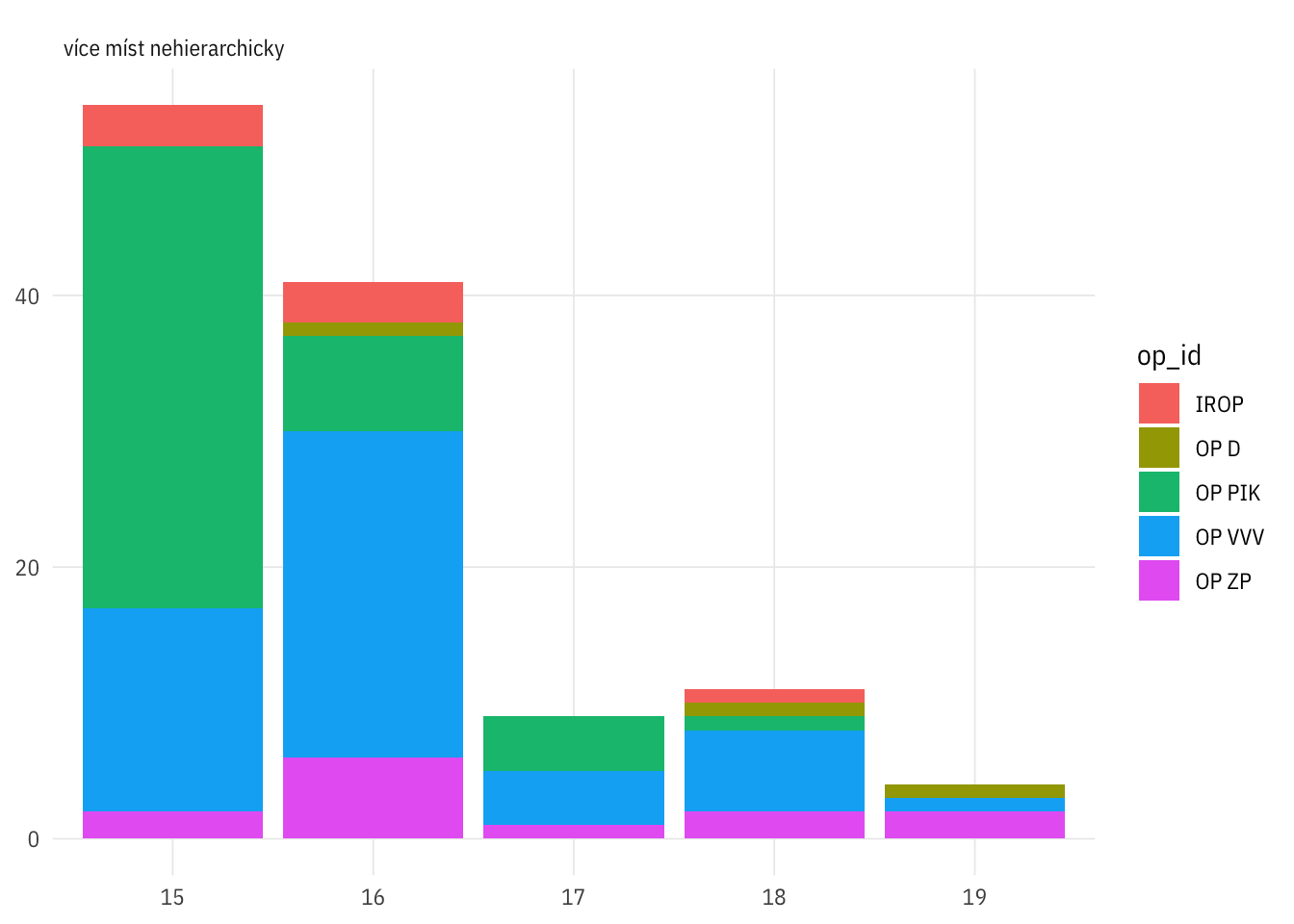
Podle OP a výzvy
prjs_groupable %>%
select(op_id, prj_id, geostatus, grp = vyzva) %>%
group_by(op_id, grp) %>%
mutate(prjs_in_grp = n()) %>%
filter(geostatus %in% c("bez místa", "více míst nehierarchicky")) %>%
group_by(op_id, grp, geostatus) %>%
summarise(pocet = n(), podil_na_skupine = pocet/mean(prjs_in_grp), .groups = "drop") %>%
mutate(podil_na_celku = pocet/sum(pocet)) %>%
arrange(desc(podil_na_celku)) %>%
mutate(cum_podil_na_celku = cumsum(podil_na_celku))Druhá kategorizace v čísle projektu
Co to je?
prjs_groupable %>%
separate(prog, into = c("cnt", "prg", "posa", "n2"), remove = F) %>%
distinct(op_id, n2) %>%
mutate(n = 1) %>%
spread(op_id, n) %>%
arrange(n2)## Warning: Expected 4 pieces. Missing pieces filled with `NA` in 2 rows [37325, 37326].Kombinace úrovní v divných projektech
prj_ids_nonhierarchical <- prjs_geostatus$prj_id[prjs_geostatus$geostatus == "více míst nehierarchicky"]library(ggupset)
gst_for_upset <- dtl %>%
filter(typ == "id" & !is.na(value),
prj_id %in% prj_ids_nonhierarchical) %>%
select(op_id, prj_id, level) %>%
distinct() %>%
mutate(level = as.character(level)) %>%
group_by(prj_id) %>%
summarise(geos = list(level)) %>%
left_join(dt %>% filter(prj_radek == 1) %>% select(prj_id, op_id)) %>%
# mutate(nr = map_int(geos, nrow)) %>%
# arrange(desc(nr)) %>%
filter(TRUE)## `summarise()` ungrouping output (override with `.groups` argument)## Joining, by = "prj_id"ggplot2::update_geom_defaults("line", list(colour = "black"))
ggplot(gst_for_upset) +
geom_bar(mapping = aes(x = geos, fill = op_id), position = "stack") +
scale_x_upset(order_by = "degree", sets = geolevels) +
# scale_y_continuous(limits = c(0, 6e4)) +
# scale_y_log10(limits = c(1, 1e5), n.breaks = 10,
# labels = scales::label_number(1)) +
# scale_y_continuous(trans = scales::log_trans(), breaks = scales::pretty_breaks()) +
ptrr::theme_ptrr() +
scale_fill_brewer(type = "qual")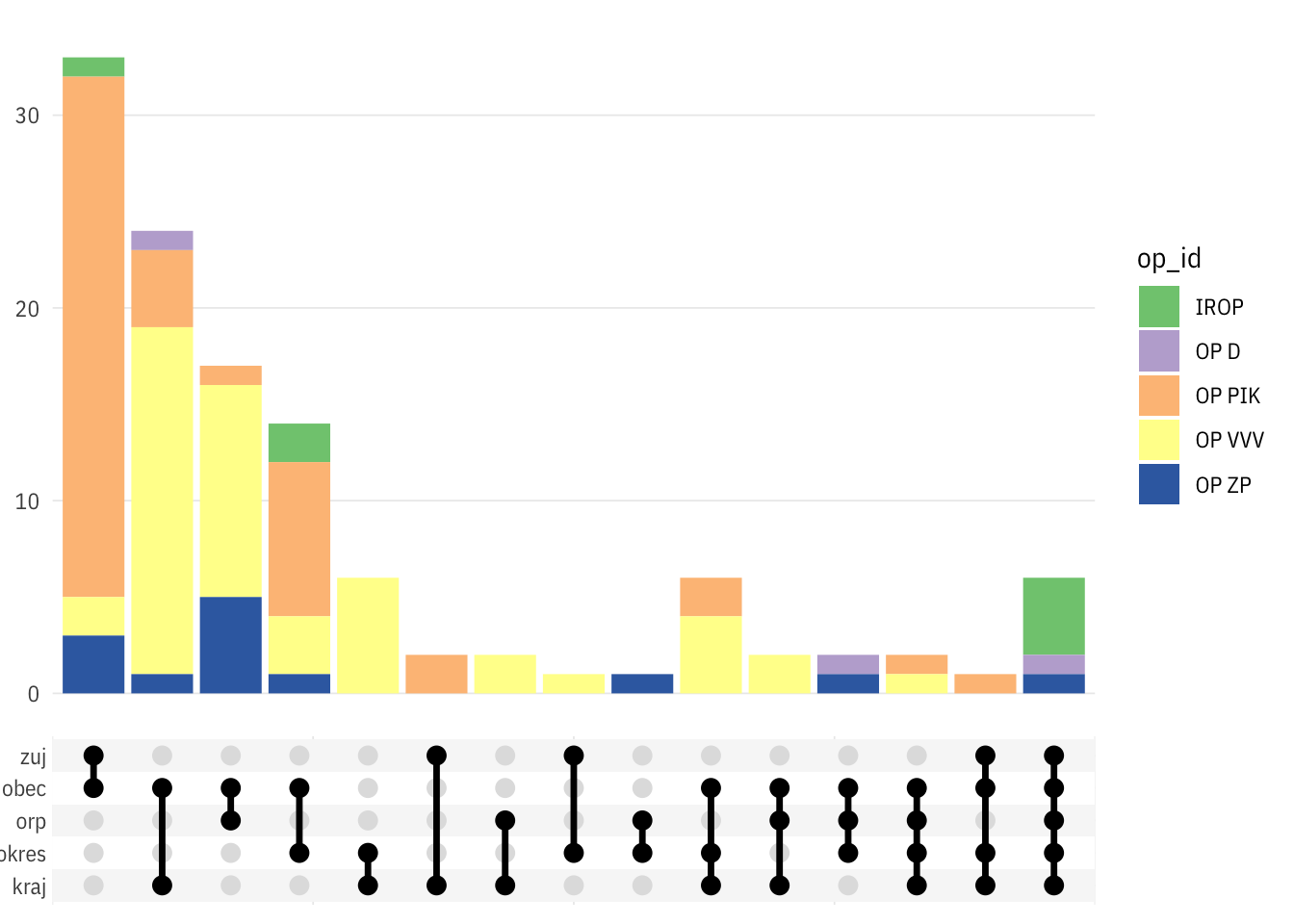
ggplot2::update_geom_defaults("line", list(colour = "darkblue"))ggplot2::update_geom_defaults("line", list(colour = "black"))
ggplot(gst_for_upset) +
geom_bar(mapping = aes(x = geos)) +
scale_x_upset(order_by = "degree", sets = geolevels) +
# scale_y_log10(n.breaks = 6, labels = scales::label_number(1)) +
# scale_y_continuous(trans = scales::log_trans(), breaks = scales::pretty_breaks()) +
ptrr::theme_ptrr(multiplot = T) +
facet_wrap(~op_id, scales = "fixed")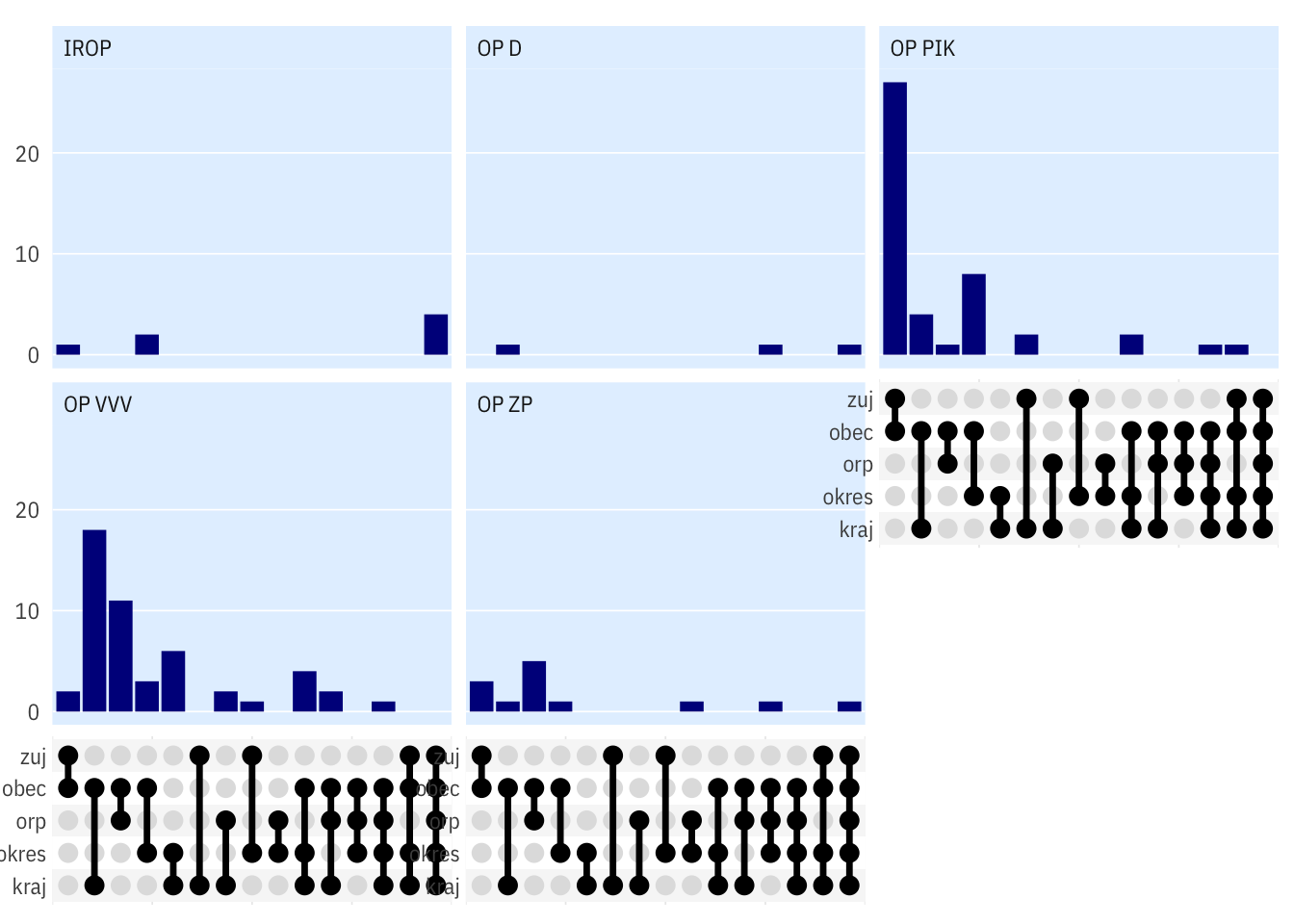
ggplot2::update_geom_defaults("line", list(colour = "darkblue"))dtl_with_geostatus <- dtl %>%
left_join(prjs_geostatus %>%
select(prj_id, geostatus)) %>%
select(op_id, prj_id, level, typ, geostatus, value) %>%
filter(typ %in% c("nazev", "id"), geostatus == "více míst nehierarchicky") %>%
drop_na(value)## Joining, by = "prj_id"dtl_with_geostatus_places <- dtl %>%
filter(typ == "id") %>%
drop_na(value) %>%
left_join(places_geostatus %>%
select(prj_id, value, level, value_has_valid_parent)) %>%
left_join(prjs_geostatus %>%
select(prj_id, geostatus)) %>%
select(op_id, prj_id, level, typ, value_has_valid_parent, value,
prj_geostatus = geostatus)## Joining, by = c("prj_id", "level", "value")
## Joining, by = "prj_id"data_geocheck_file <- here::here("data-processed", "dt-geohierarchy-check.parquet")
data_geocheck <- read_parquet(data_geocheck_file)
# data_geocheck %>%
# filter(prj_id %in% prj_ids_nonhierarchical) %>%
# arrange(prj_id)data_geocheck %>%
group_by(prj_id, level, value) %>%
filter(all(!levels_ok)) %>%
# filter(str_detect(prj_id, "CZ.04")) %>%
ungroup() %>%
count(prj_id, sort = T)